

Advertencia de «guerras climáticas» en medio del debate sobre la siembra de nubes y la lluvia en Dubai
Las lluvias fueron las más intensas que han experimentado los Emiratos Árabes Unidos en 75
 Advertencia de «guerras climáticas» en medio del debate sobre la siembra de nubes y la lluvia en Dubai
Advertencia de «guerras climáticas» en medio del debate sobre la siembra de nubes y la lluvia en Dubai
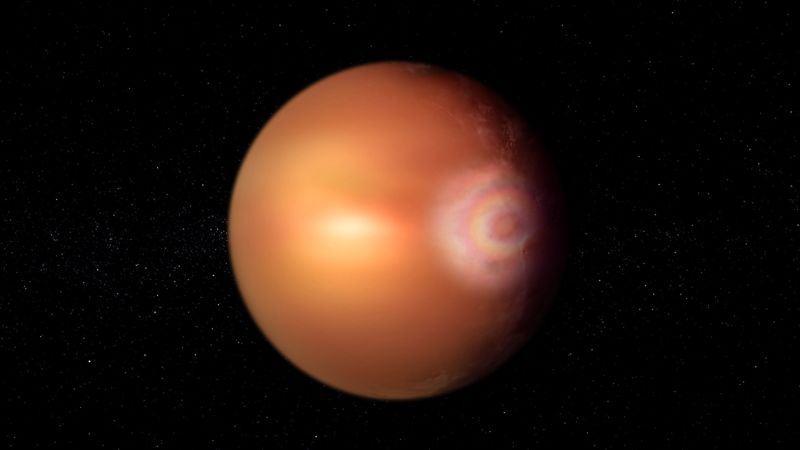 Un fenómeno parecido a un arco iris puede estar brillando en el infernal exoplaneta WASP-76b
Un fenómeno parecido a un arco iris puede estar brillando en el infernal exoplaneta WASP-76b
 X llama a Google un 'compromiso' después de que Elon Musk revelara un consejo: esto es lo que sucede cuando escribes 'Antes: 2023'
X llama a Google un 'compromiso' después de que Elon Musk revelara un consejo: esto es lo que sucede cuando escribes 'Antes: 2023'
Las lluvias fueron las más intensas que han experimentado los Emiratos Árabes Unidos en 75
Suscríbase al boletín científico Wonder Theory de CNN. Explora el universo con noticias sobre descubrimientos
Los usuarios de las redes sociales han llamado a Google una «plataforma comprometida» después de
La edición de hoy de Viral Foods presenta un arroz de color azul que ha
Los tres médicos dicen que la mejor dieta para las personas con artritis inflamatoria (como
Apple lanzó la segunda versión beta pública de su próxima actualización macOS Sonoma 14.5, invitando
Hackers internacionales violan datos confidenciales en Israel, dicen medios locales Los medios israelíes informaron que
Una medida en un año electoral en Estados Unidos podría hacer subir los precios del
Acercarse / El cohete SLS se ve en su plataforma de lanzamiento en el Centro
OnePlus está listo para expandir su línea de productos de tabletas Android. Según se informa,





